
Composable resume management
I built cv because I wanted a resume system that treated my career history like durable data instead of a pile of disconnected documents. The app is a lightweight FastAPI workspace for composing resumes from reusable sections, managing a shared directory of structured content, and exporting the same source material into multiple polished deliverables.
What I cared about most was keeping the editing model honest. I did not want a brittle page of ad hoc form fields that duplicated business logic in the UI. Instead, cv keeps the canonical record in a normalized SQLite-backed model, then draws a clean boundary around that data with Pydantic before it ever reaches the interface or the renderer. That let me move quickly without sacrificing the structure I need for repeatable exports.
What the app does
- Compose resumes from reusable records rather than one-off documents
- Keep shared resume content in a directory that can be reused across variants
- Export both structured JSON and rendered documents from the same source of truth
- Generate PDF output through WeasyPrint so the final artifact stays publication-ready
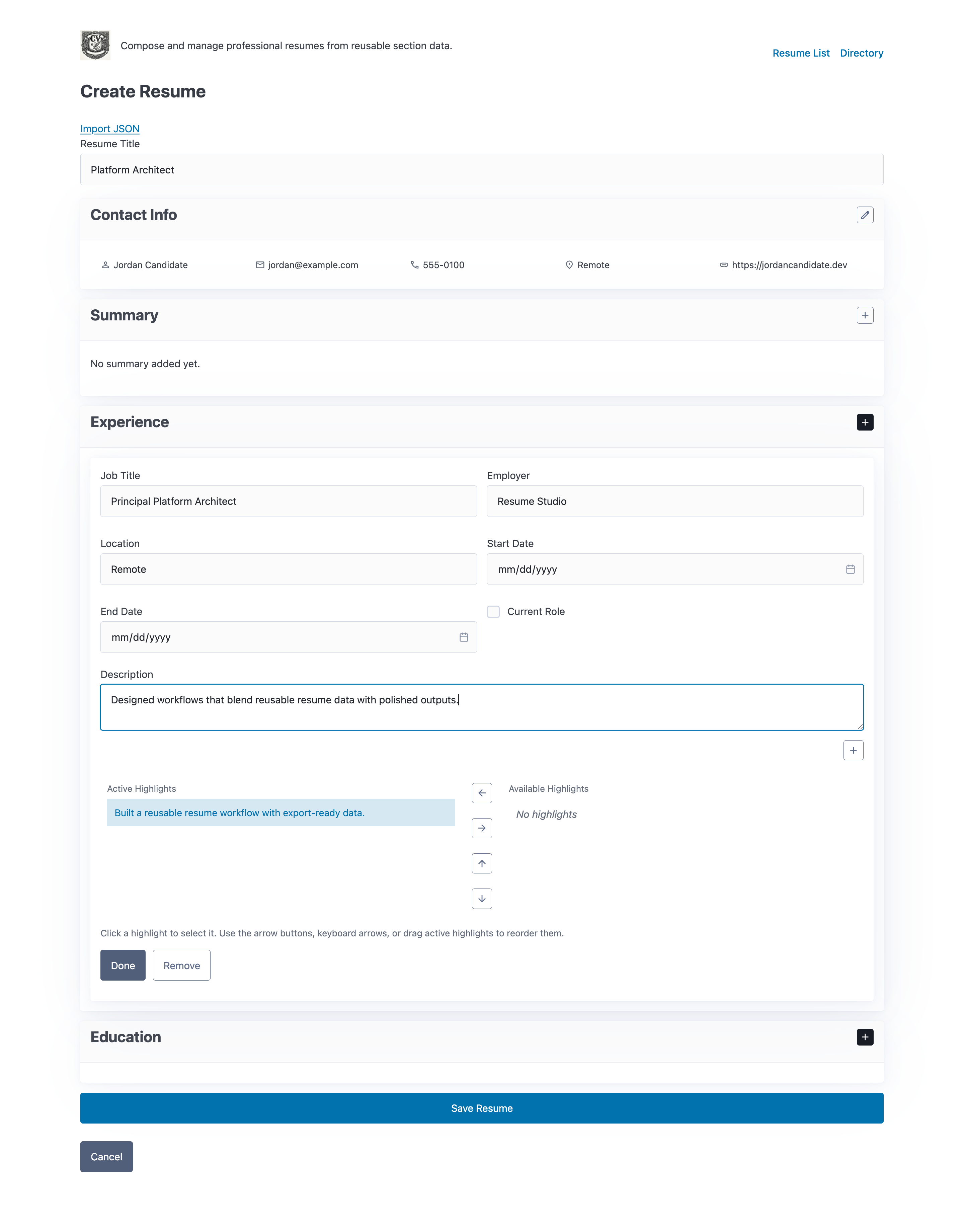
The composer is where I assemble a target resume from shared, structured sections instead of rewriting content by hand.
The composer is the center of gravity. I can start with a base profile, adjust the order and emphasis for a specific role, and keep the underlying content reusable for the next version. That matters when I am iterating on multiple resume variants, because the important work becomes curation rather than re-entry.
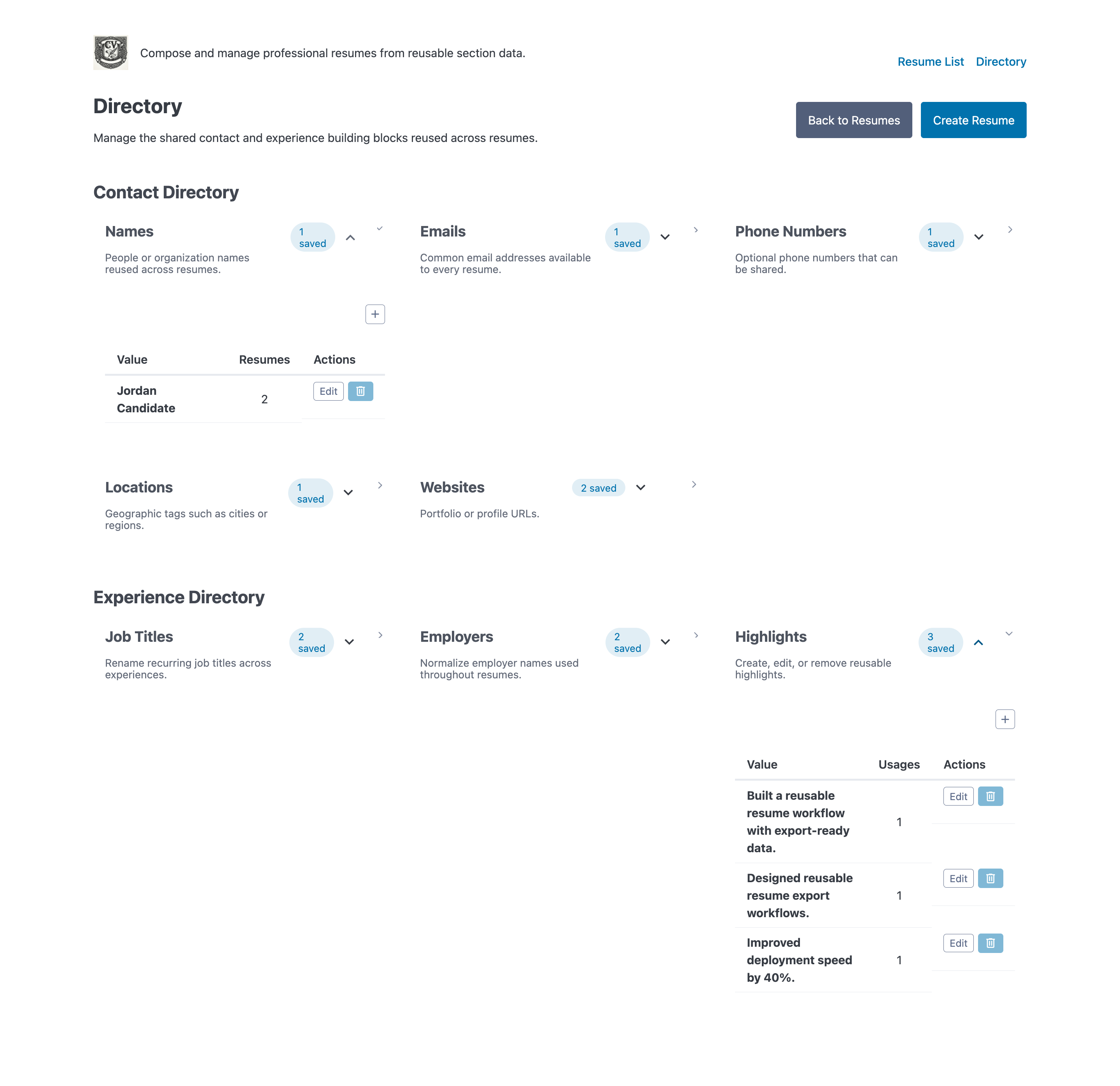
A shared directory keeps the reusable resume pieces organized so I can build new outputs without losing track of the source material.
The shared directory is where the project starts to feel like a workspace instead of a single document. I wanted one place for experience, education, skills, and supporting assets so I could compose, revise, and export without copying content across files or losing track of which draft was authoritative.
Rendering and export pipeline
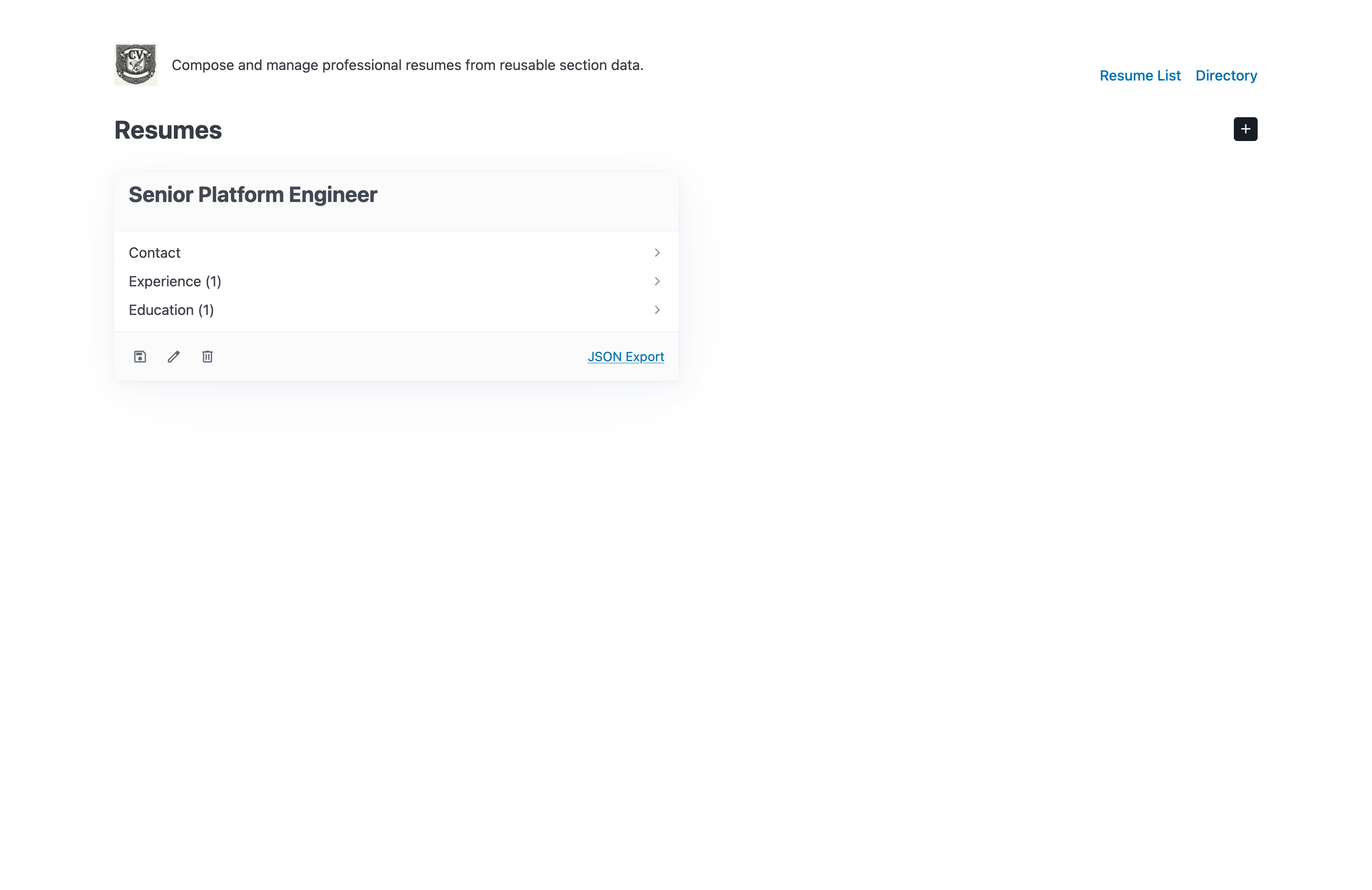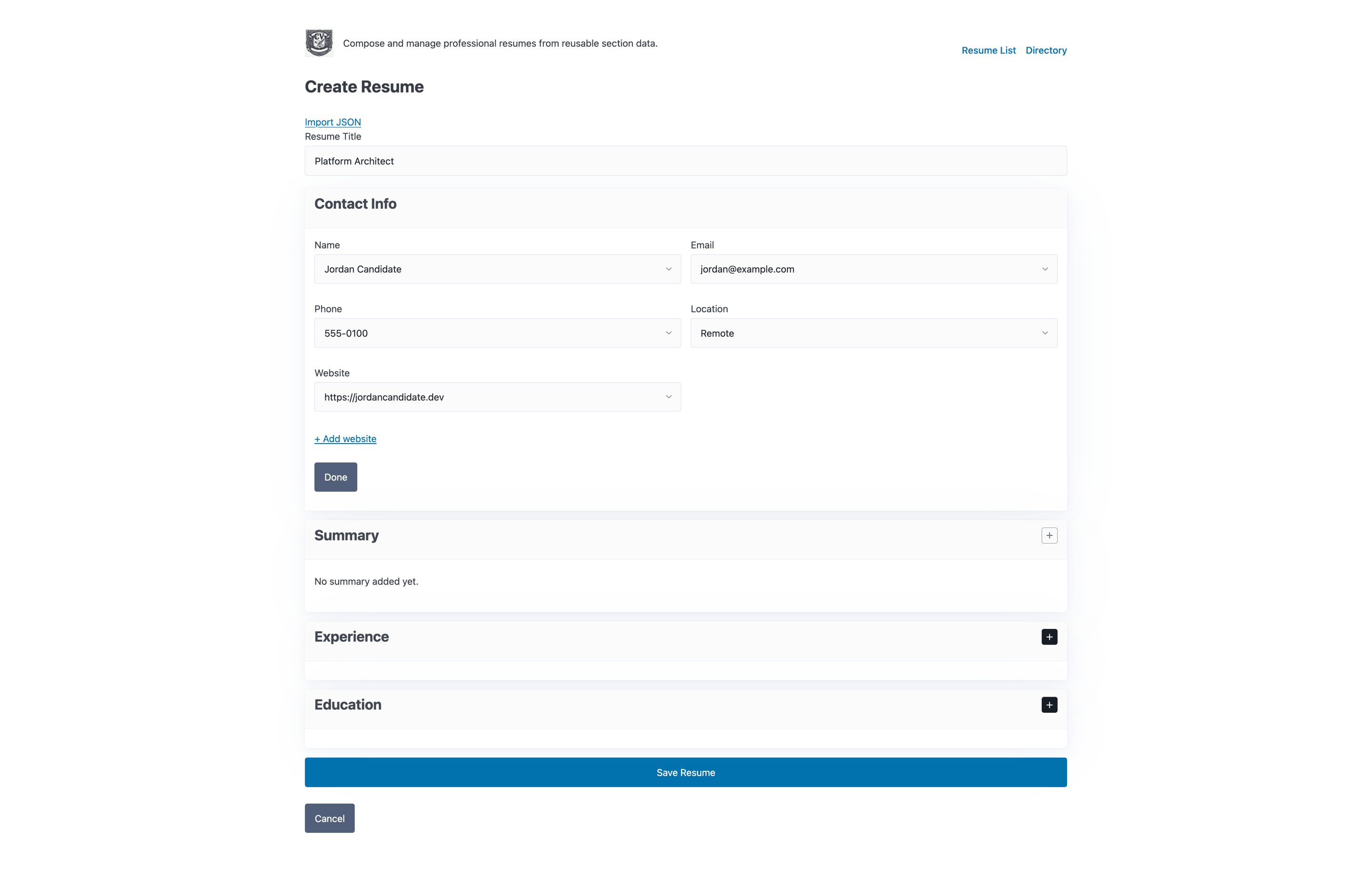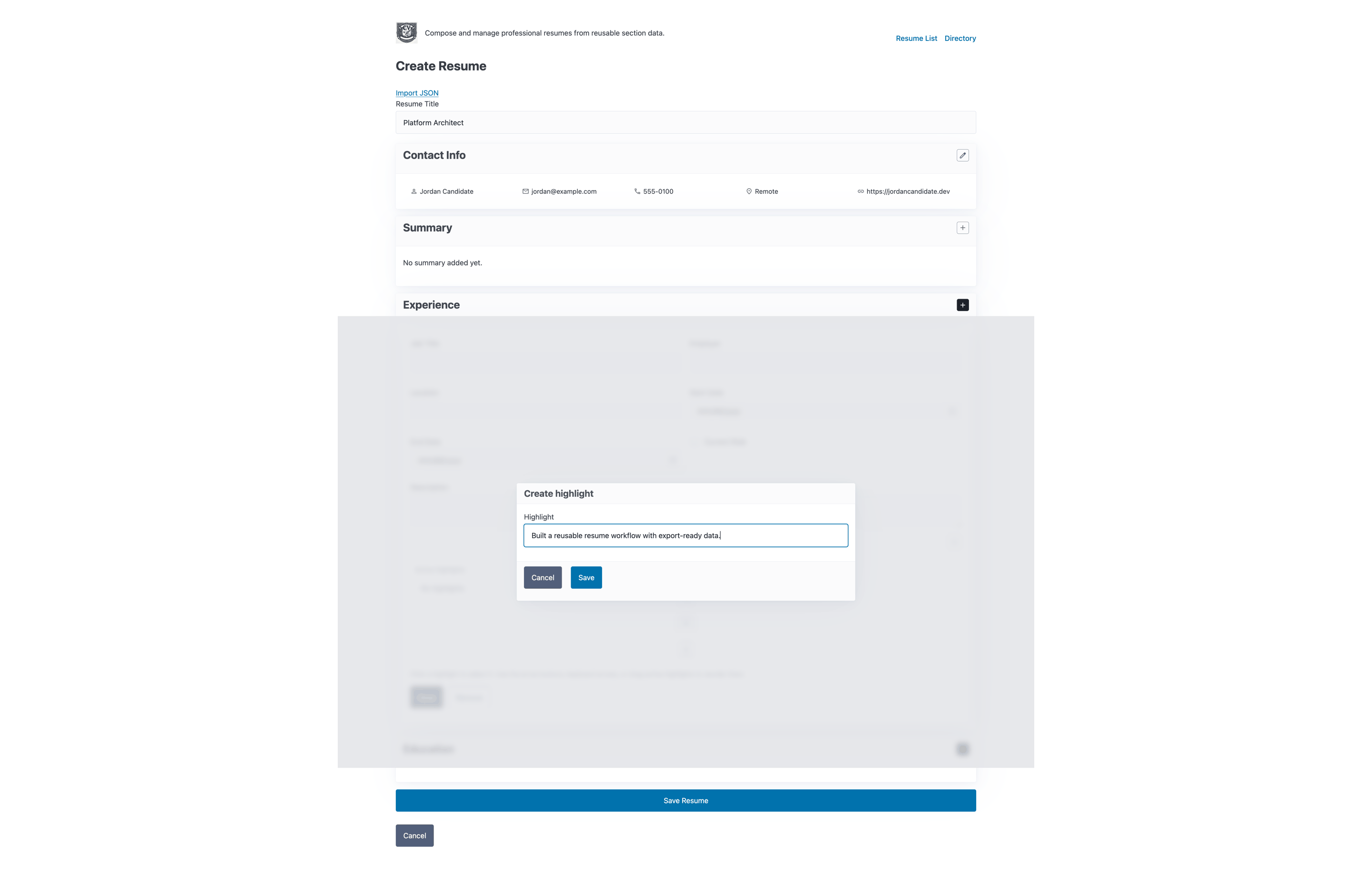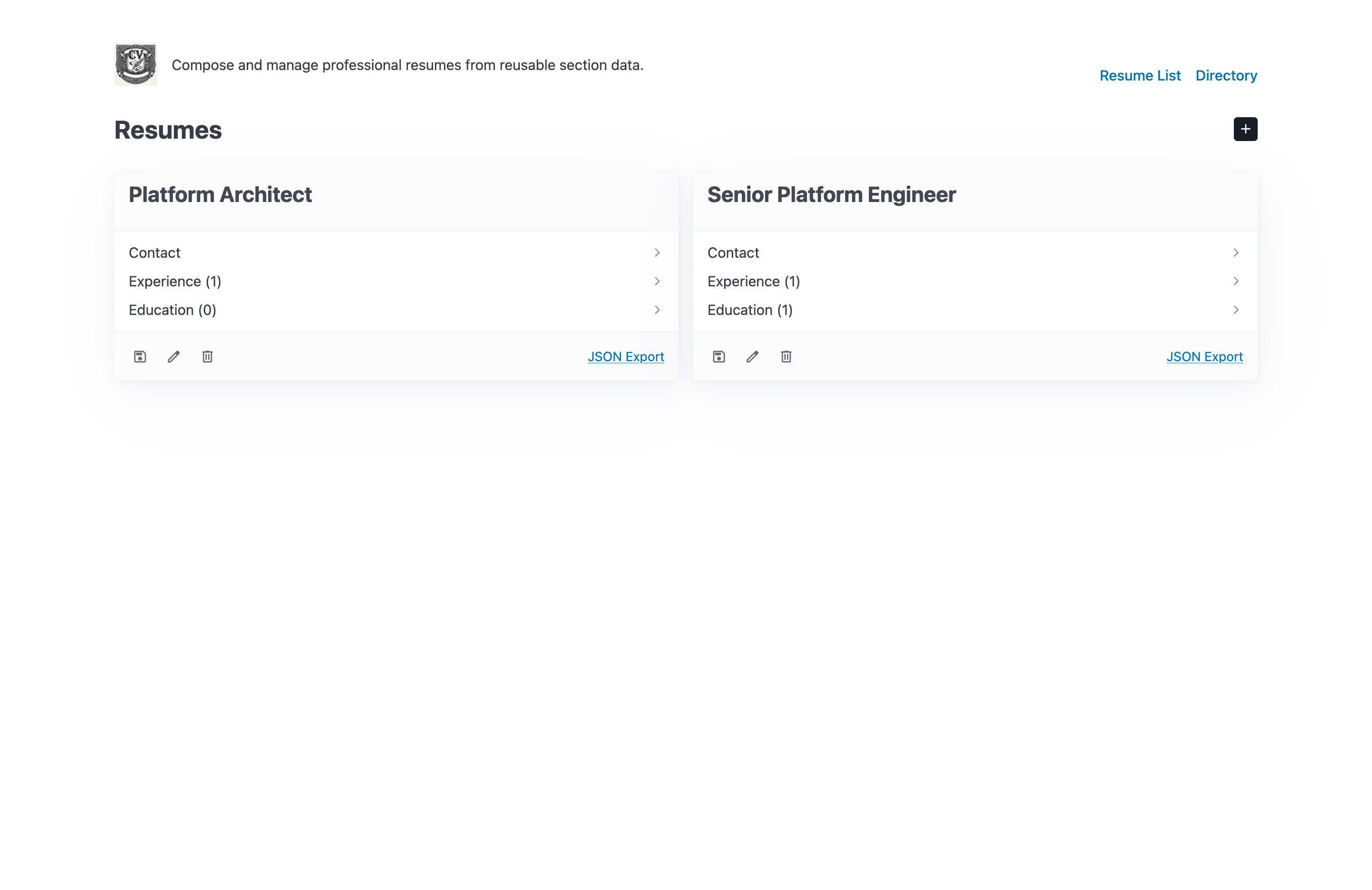
Editing stays fast because the interface leans on HTMX-driven interactions rather than a heavy client application.
I kept the UI intentionally light: FastAPI on the backend, SQLite for persistence, and Jinja templates enhanced with HTMX, Web Components, and Pico CSS. That combination gave me enough interactivity to make the app feel responsive while avoiding the overhead of a full frontend build system. The result is a tool that is easy to run locally, easy to reason about, and still pleasant to use.

JSON export exposes the normalized data model directly, which makes the workspace useful for automation and downstream tooling.
The JSON export is not just a convenience feature; it is the proof that the app is actually data-first. I can inspect the exact structured payload behind a resume, feed it into another workflow, or regenerate the document later without reconstructing the content by hand. That is the piece that makes cv feel reusable rather than disposable.
Why this architecture held up
- FastAPI gave me a clean backend surface for forms, exports, and document generation.
- SQLite kept persistence simple enough for local development while still being durable and inspectable.
- Pydantic boundaries kept the API and rendering layers honest about what the resume data actually looks like.
- WeasyPrint let me move from structured content to a polished PDF without inventing a custom print pipeline.
- Jinja, HTMX, Web Components, and Pico CSS were enough to make the app feel modern without making it heavy.
What I was optimizing for
I was not trying to build the biggest resume platform. I was trying to build the smallest useful one: something that would let me maintain one structured source of truth, spin up new variants quickly, and export confidently when it was time to share or print. cv gives me that workflow, and it does it without hiding the data model behind a lot of ceremony.
The project also changed how I think about resumes themselves. Once the content is normalized and reusable, the document becomes an output format rather than the center of the system. That shift made the whole thing easier to extend, and it made future edits feel like maintenance instead of reinvention.